Data plays a central role in all digital technology usage, so it is imperative that the data is usable, secure, and current. But for data to be of any value, it needs to be structured and stored in a manner that allows scalable collection and sorting. To enable this, businesses are creating central data catchment areas, called data lakes. AWS provides the services and tools needed to build these natively and store all your data—structured and unstructured. Building data lakes on AWS is highly beneficial as it ensures security, efficiency, scalability, and cost benefits. Services that need to process and manage the data are also configured on AWS’s datalake—automatically.
Because of the enormous amount of data, and its disparate nature, held in the data lake, it can be tough to access specific data. (Extract Transform Load) ETL tools are fundamental to be able to locate, prepare and load the data into meaningful content that users can utilize for various business needs.
CDK Pipeline on AWS Data Lake
A Cloud Development Kit (CDK) is simply an open-source framework for software development used by engineers to define resources using a familiar programming language. To enable CDK applications to be delivered seamlessly, a CDK pipeline is used. The pipeline automatically updates itself when a new application is added.
AWS’s Cloud Development kit comes with CDK pipelines integrated, automating releases and enabling focused app development and delivery on the data lake.
Using AWS CDK pipelines organizations can implement a DevOps strategy for ETL jobs in a manner that supports continuous deployment and delivery, data processing, and test cycles.
In order to begin ETL jobs, we first need to build a data lake—for instance, AWS Simple Storage Service (S3)—in three discrete but interconnected buckets:
Bronze Bucket: This is where the raw data received from a variety of sources is stored
Silver Bucket: Here the raw data is checked to ensure correctness, avoid duplication, etc. This is stored in formats that support quick retrieval, for instance, Parquet or similar formats.
Gold Bucket. The gold bucket cater to specific use cases and thus the data is transformed according to those needs.
Here’s what the process typically looks like:
1. Data in its raw form is uploaded to the AWS S3 bronze bucket
2. Automatically, the Lambda function comes awake and inserts a piece of code to the Amazon DynamoDB table to monitor the file processing status.
3. After this, AWS Glue transfers the input data from the bronze bucket to S3’s silver bucket.
4. AWS Glue moves this data to the gold bucket, which is custom-built for a specific purpose.
5. The data is stored in a Parquet or similar format according to ETL transformation rules.
6. The DynamoDB table is duly updated
7. The data is now ready for onward action—analyses, reports etc.
Design requirements & principles for ETL deployment using CDK pipelines
You will need the following items to build this model
· Dedicated Amazon Web Servicer account (in order to run a CDK pipeline)
· One or more AWS account—depending on usage—wherever the data lake exists
· A landing zone (containing a repository for the code)
· Bespoke source code repository with a unique AWS service, orchestration, and configuration requirements for each ETL
· Dedicated source code repository for the building, deployment, and management of ETL jobs.
Other resources needed for the deployment:
CDK Application, CDK Pipelines, Amazon DynamoDB, AWS Glue, and AWS Step Functions.
You also need AWS Key Management Service (KMS) encryption keys, Amazon Virtual Private Cloud (Amazon VPC), subnets, VPC endpoints, route tables, AWS Secrets Manager, and security groups.
Benefits of using CDK pipelines for ETL deployment of AWS data lake
There are a number of benefits to using CDK pipelines to deploy data lake ETL. These include:
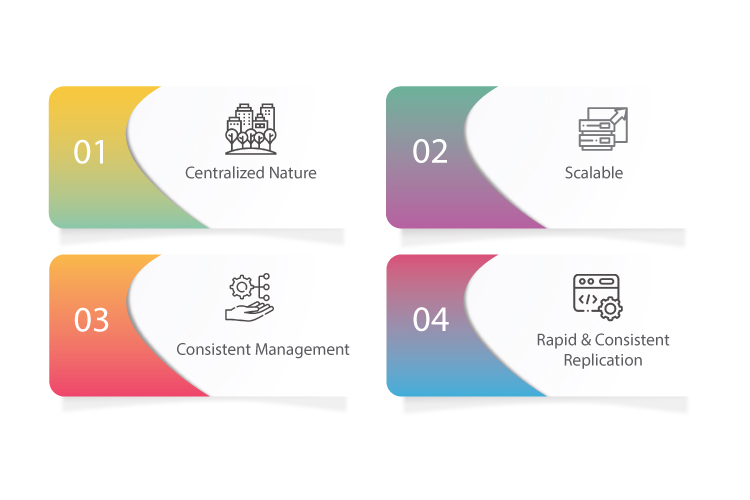
Centralized nature: This gives developers control over deployment code, strategy, and enables end-to-end automation.
Scalable: Being scalable means allows easy expansion into multiple accounts—each pipeline responsive to bespoke control within its environment
Consistent management: Since the model is designed to enable the configuration-driven deployment, you get control of all global configurations; for instance: resource names, regions, VPS CIDR ranges, AWS A/c Id’s, etc.
Rapid & consistent replication: As code changes are securely repeated in all the environments, the model can be easily repeated to ensure consistent deployment of new ETL jobs.
CDK pipelines offer a scalable, speedy and consistent model to deploy data lake ETL jobs in AWS environments. The process outlined in this article can help you automate your system with CDK pipelines to run ETL jobs on your AWS data lake.