Introduction:
Use case 1: ETL Processes Over the Cloud:
In automated data pipeline architecture, we utilized two distinct accounts: the Data Account and the Application Account. The Data Account was allocated access to AWS services primarily associated with data storage units, such as S3 buckets. These buckets facilitated the transmission of data to and from the Application Account. Within the Application Account, various applications or services, including Glue and Lambda, were deployed to manipulate the data, generate issue tickets, or provide notifications regarding ongoing processes.
In terms of infrastructure management and source code deployment, we relied on Terraform, which served as the backbone of our setup. Terraform was responsible for orchestrating infrastructure resources and deploying source code across the architecture. Additionally, the implementation of Continuous Integration/Continuous Deployment (CI/CD) processes was carried out using GitLab. GitLab facilitated the automation of code testing, integration, and deployment workflows throughout the development lifecycle.
Timelines:
Our experienced team understood their vast and complex infrastructure to tailor the services and strategies to be applied to their infrastructure.
2. Legacy Flow Setup:
2.1. Data Synchronization (Data Sync):
The source data originally resided on-premises and needed to be transferred to S3 for subsequent ETL (Extract, Transform, Load) processes to extract the required information through queries. However, it was imperative to ensure that incoming data to our servers remained synchronized to prevent any loss or leakage, which could be detrimental in an industrial context. Therefore, a robust data synchronization process was implemented to maintain this synchronization, providing a critical advantage by ensuring that our data remained consistent across the various data repositories and buckets required for the ETL processes.
The data synchronization process involved collecting data from on-premises servers, specifically from Mainframe and Informatica systems. This data was then transferred to our servers, where synchronization occurred between the Mainframe, Informatica, and our internal server systems. This ensured that the data remained consistent and up to date across all platforms, facilitating seamless data transfer and processing.
Several common tools were employed to facilitate this synchronization process, including AWS CloudWatch, AWS EventBridge, Lambda functions (specifically, those responsible for handling ETL success/failure events – named tui-etl-successfailevent-sns-{env}), SNS (Simple Notification Service), SNS Topics, and Service now for ticketing solution. These tools collectively enabled real-time monitoring, event-driven synchronization, and notification mechanisms to ensure the smooth operation of the data synchronization process and prompt resolution of any issues that arose.
2.2. The Processing layers:
Processing in the automated environment happened in 3 layers namely landing layer, raw layer, and conformed layer
2.2.1. Landing Layer:
Services used: S3 bucket (grp2-landing/tui/legacy), SQS, lambda (tui-copyprefix-lambda-{env}), and Glue (tui-copy-glue1).
Steps:
a. The data on sync was in raw format and no process can be done on it.
b. The raw data files in JSON format will be moved to the S3 bucket which we call as landing bucket
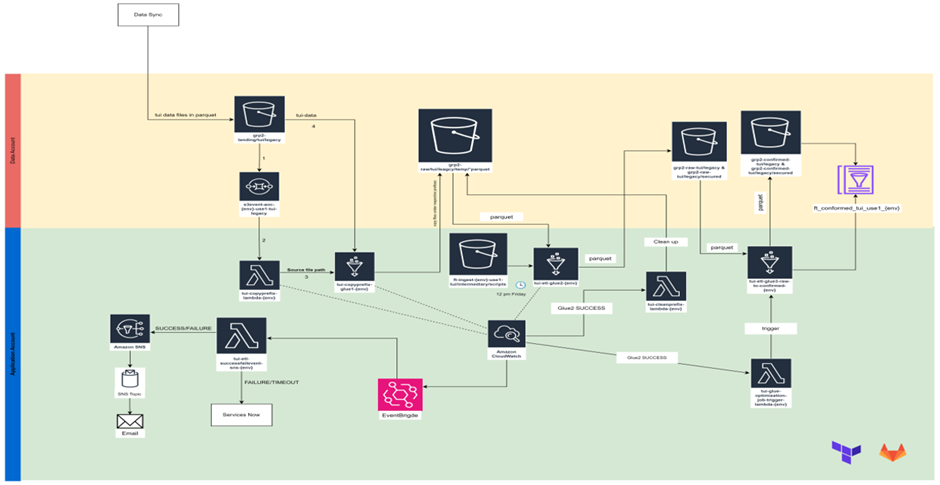
c. When files were entered into the bucket, SQS services had same number of messages as the number of files entered the bucket.
d. Each SQS message triggered the same lambda function, which initiated Glue job 1.
e. Glue job 1 was responsible for fetching data from the landing bucket and copying it with respective prefixes into the legacy bucket, storing it in parquet format.
f. CloudWatch and EventBridge were employed to monitor the status of the Lambda and Glue processes, whether they were working or not upon being triggered.
2.2.2 Raw Layer:
Services Used: S3 bucket (grp2-raw/tui/legacy/temp), S3 bucket (ingest-scripts), Glue (glue-2-{env}), Lambda (tui-cleanprefix-lambda-{env})
Steps:
At a specific time on the selected day (12 PM Friday), Glue Job 2 was scheduled to run, with the necessary scripts for the job located inside the Application Account S3 bucket.
a. Glue Job 2 was tasked with extracting parquet files from the legacy buckets, transforming and classifying them into categories of secured and legacy, and subsequently storing them into the respective buckets within the conformed layer.
b. The state of Glue Job 2 was monitored using the same CloudWatch and EventBridge infrastructure.
c. Upon successful completion of Glue Job 2, another lambda function (tui-cleanprefix-lambda-{env}) was triggered. This lambda function was responsible for deleting the files under the raw layer within the temp folder.
d. Concurrently, another lambda function was triggered immediately after the successful completion of Glue Job 2. Further details about this lambda function will be provided in the subsequent section.
2.2.3 Conformed Layer:
Services Used: S3 buckets (grp2-raw-tui-legacy and grp2-raw-tui-secured), S3 bucket folders (grp2-confirmed-tui/legacy and grp2-confirmed-tui/legacy/secured), Glue (glue job 3 raw-to-confirmed-{env}), Lambda (tui-glue-optimization-job-trigger-lambda-{env})
a. After the successful completion of Glue Job 2, the lambda function in this layer, specifically tui-glue-optimization-job-trigger-lambda-{env}, was triggered, initiating Glue Job 3.
b. Glue Job 3 (tui-etl-glue3-raw-to-confirmed-{env}) commenced its execution, tasked with placing the parquet files into respective folders based on whether they were classified as legacy or secured files. Additionally, Glue Job 3 conducted the ETL process and prepared the Glue table for further analysis.
c. Once the Glue table was prepared, it became accessible for querying using AWS Athena.
2.2.4 What if a glue job fails?
a. In the event of a failure in any Glue job, the entire automation process becomes ineffective. Hence, all jobs are diligently monitored using common tools.
b. When a job is initiated, comprehensive logs are generated in AWS CloudWatch, capturing details of its execution status and any associated issues, such as file or script errors.
c. EventBridge is configured to capture the state change of glue job and trigger a designated lambda function (tui-etl-successfailevent-sns-{env}). This lambda function is designed to send out email notifications through AWS SNS in case of successful job execution.
d. However, if a job encounters a failure during execution, the lambda function swiftly responds by raising a ticket to alert the technical team for further investigation and resolution. This ensures that any issues disrupting the automated workflow are promptly addressed, maintaining the reliability and effectiveness of the data pipeline automation.
3. Legacy Support Flow Setup
What if we get a failover in the workflow? This question should arise as no system is cent percent failproof. So, we need to have a setup that if a failure is seen at least some manual triggers can come handy.
3.1 Manual operations in each Processing Layers
Like the Legacy flow setup Legacy Support flow also has three layers namely landing layer, raw layer & conformed layer.
Services Used: Amazon CloudWatch, Lambda (tui-etl-successfailevent-sns-{env}), Amazon SNS, SNS Topic, Amazon EventWatch.
3.1.1. Landing Layer:
Services Used: S3 bucket (landing bucket), Glue1 (tui-copyprefix-glue1-{env}), lambda (tui-copygluetrigger-support-{env}), lambda (cleanup)
Steps:
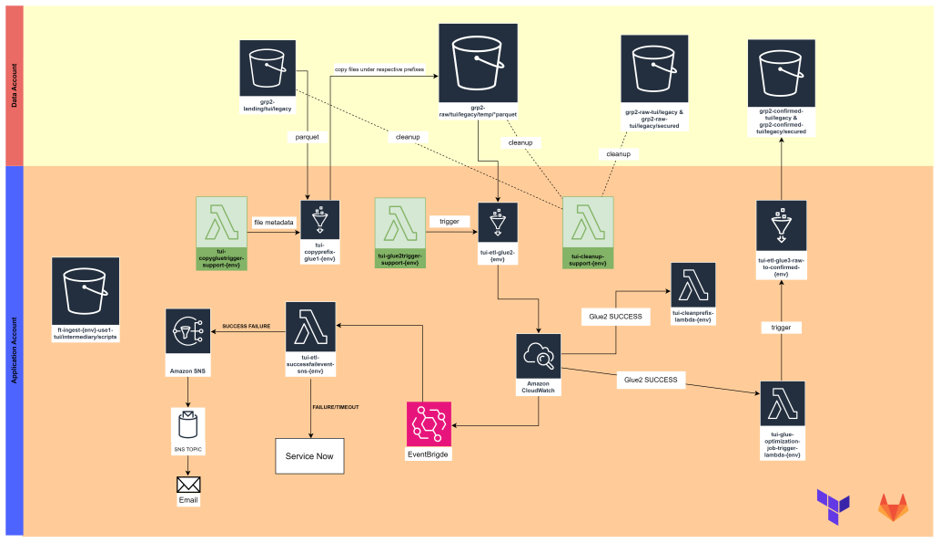
c. We must put a file inside the S3 bucket folder (ft-ingest-{env}-use1-tui/intermediary/scripts) using gitlab pipeline (separate stage is created), and that file triggers the lambda service based on put event.
d. The file for this S3 prefix could be inserted into the folder by utilizing the GitLab Pipeline to trigger a lambda function, subsequently leading to the triggering of the Glue job.
e. Following an incomplete or unsuccessful procedure, cleanup was conducted using a cleanup lambda service. The file required to execute that lambda script was also placed into the scripts folder via the GitLab pipeline.
f. The cleanup lambda was responsible for removing unprocessed files or files containing any issues.
g. Upon completion, the formatted parquet files were stored in the Legacy Layer bucket.
Services Used: S3 bucket (grp2-raw/legacy), Lambda (tui-glue2trigger-support-{env})
Steps:
3.1.3. Conformed Layer:
Services Used: S3 bucket (grp2-confirmed-tui/legacy and confirmed), Lambda (tui-glue2trigger-support-{env})
Steps:
3.1.4. Job of Common Tools/Services:
Use Case 2: Data Migration from IBM DB2 To Amazon Redshift:
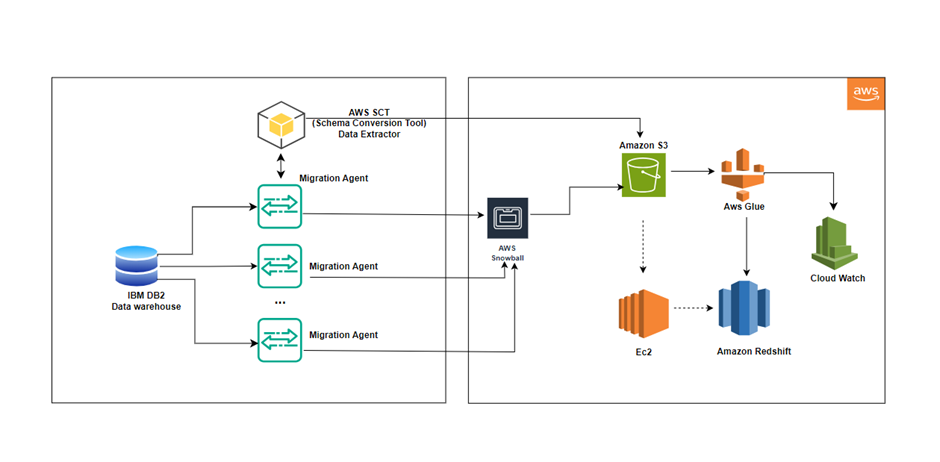
This document details the successful migration of the data from [Source System Name, e.g., IBM DB2] to Amazon Redshift, a cloud-based data warehouse service offered by Amazon Web Services (AWS). We leveraged AWS Snowball for efficient data transfer, Amazon S3 for scalable storage, and AWS Schema Conversion Tool (SCT) to automate schema conversion and data loading into Redshift. We also explored the potential use of AWS Glue jobs for additional data processing needs.
Benefits of Using AWS for Data Migration:
High-Level Overview:
The data migration process involves the following steps:
2.1 Snowball Job and Data Extraction Agent Setup
2.2 Data Transfer to Snowball
Use case 3: GenAI Implementation to Generate MCQs from given documents:
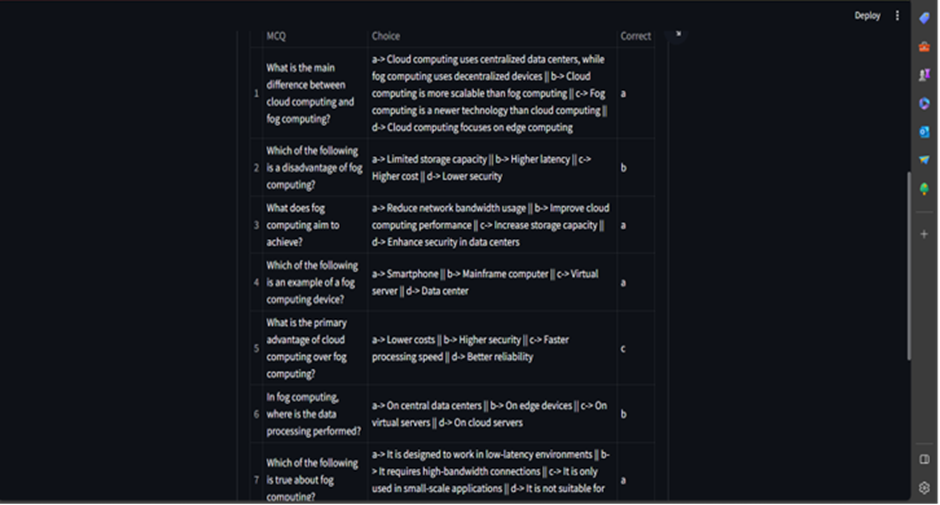
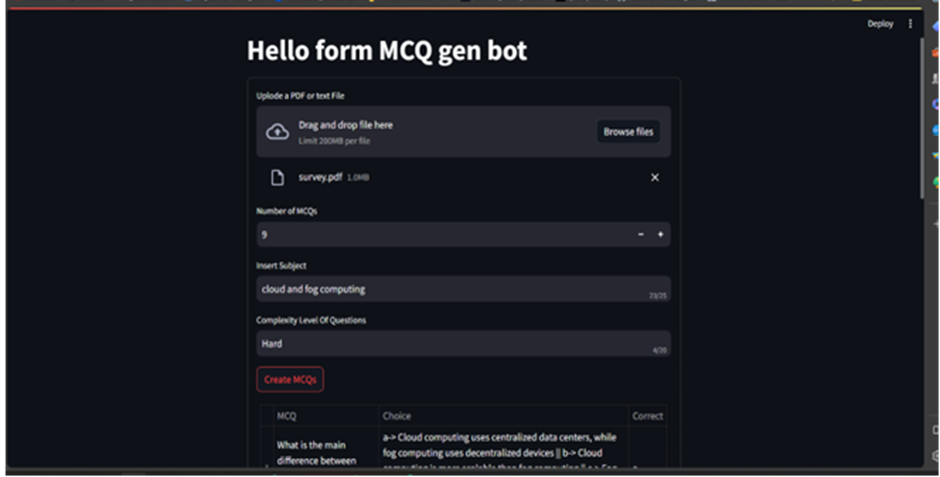
Crafting questions that target specific difficulty levels, even for domain experts, can be incredibly challenging. This project tackles that very problem, proposing a novel solution powered by GenAI. Instead of relying on manual effort, GenAI automatically generates questions along with their corresponding correct answers, streamlining the evaluation process. This not only saves valuable time and resources but also ensures consistency and objectivity in difficulty assessment. In simpler terms, GenAI takes the burden of question creation off your shoulders, while simultaneously guaranteeing precise difficulty control, offering a significant leap forward in educational assessment and knowledge evaluation. This setup for the client was done and it is running on their local setup.
Foundational Model: Gemini-Pro by Google
Libraries Used: Langchain, PyPDF2, etc. (for os and system level configuration)
Pros.
Cons.